PythonとBokehを使ってグラフを描く方法のまとめ2回目です。今回は簡単なグラフの見た目変更を行います。
サンプルとしては第1回で使用した棒グラフのコードを引き続き使います。
<python>
#使用モジュール宣言
from bokeh.plotting import figure, show
#グラフの要素
#X軸が月、Y軸が気温
x = [1, 2, 3, 4, 5, 6]
y = [2, 1, 6, 12, 16, 21]
#Figureクラスからインスタンスを生成
#グラフのサイズを縦300ピクセル、横300ピクセルに設定
p = figure(width=300, height=300)
#vbarメソッドでグラフを描画
#X軸のデータをx、Y軸のデータをyに設定
p.vbar(x=x, top=y)
#グラフ描画
show(p)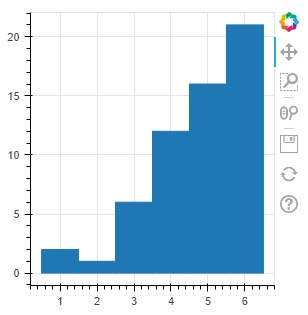
グラフのサイズ変更
グラフのサイズを変更する場合、figureクラス内のwidthとheightを指定することで変更が可能です。サンプルでは300ピクセル四方としています。
数字を書き換えることで任意のサイズに変更可能です。グラフの形状によって任意の大きさにすると見やすくなると思います。
400ピクセル四方に変更してみました。
棒グラフの幅変更
サンプルの棒グラフは棒と棒の間隔が完全に埋まっているので、いわゆる棒グラフっぽい見た目になっていません。この幅についても自由に調節可能です。
棒の幅はvbarクラスのwidth属性で設定します。デフォルトの設定では1なので、少し細めに0.75に設定してみます。サンプルのコードにはないので追記します。
結構棒グラフっぽい見た目になったのではないでしょうか。
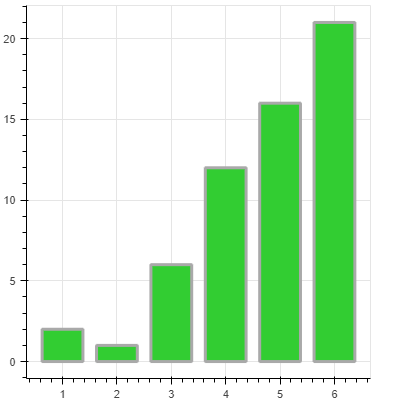
棒グラフの色変更
棒グラフの色を変更します。グラフの色はvbarクラスのfill_color属性で設定します。色に関してはHTMLカラーコードか、CSS文字列でも設定が可能です。今回はHTMLカラーコードでlimegreen(#32cd32)に設定しました。
カラーコードはシングルクォーテーションでくくらないとエラーになってしまうので注意が必要です。
棒グラフの枠線描画
棒グラフの枠線ももちろん変更可能です。枠線の太さはvbarクラスのline_width属性で設定します。デフォルトの太さは1.0となっています。今回は分かりやすくするため3.0に設定しました。
棒グラフの枠線色変更
棒グラフの枠線色はvbarクラスのline_color属性で設定します。fill_color属性同様HTMLカラーコードかCSS文字列で設定可能です。今回の例ではdarkgray(#a9a9a9)に設定しました。
できあがったグラフはこのようになりました。
編集したコードは以下の通りです。
#<python>
#使用モジュール宣言
from bokeh.plotting import figure, show
#グラフの要素
#X軸が月、Y軸が気温
x = [1, 2, 3, 4, 5, 6]
y = [2, 1, 6, 12, 16, 21]
#Figureクラスからインスタンスを生成
#グラフのサイズを縦400ピクセル、横400ピクセルに設定
p = figure(width=400, height=400)
#vbarメソッドでグラフを描画
#X軸のデータをx、Y軸のデータをyに設定
p.vbar(x=x, top=y, width=0.75, fill_color='#32cd32', line_width=3.0, line_color='#a9a9a9')
#グラフ描画
show(p)以上のように、コード内でパラメータを設定することで表計算ソフト同様にグラフの見た目を自由に変更可能です。
表計算ソフトならGUI上で”グラフの書式設定”のような項目を使って変更できるのでコードで編集するのは大変に感じますが、かなり自由度の高いカスタマイズが可能な点、コードの処理次第で自動的に色を変えるなど見た目の設定を自動化できる点などが優れています。